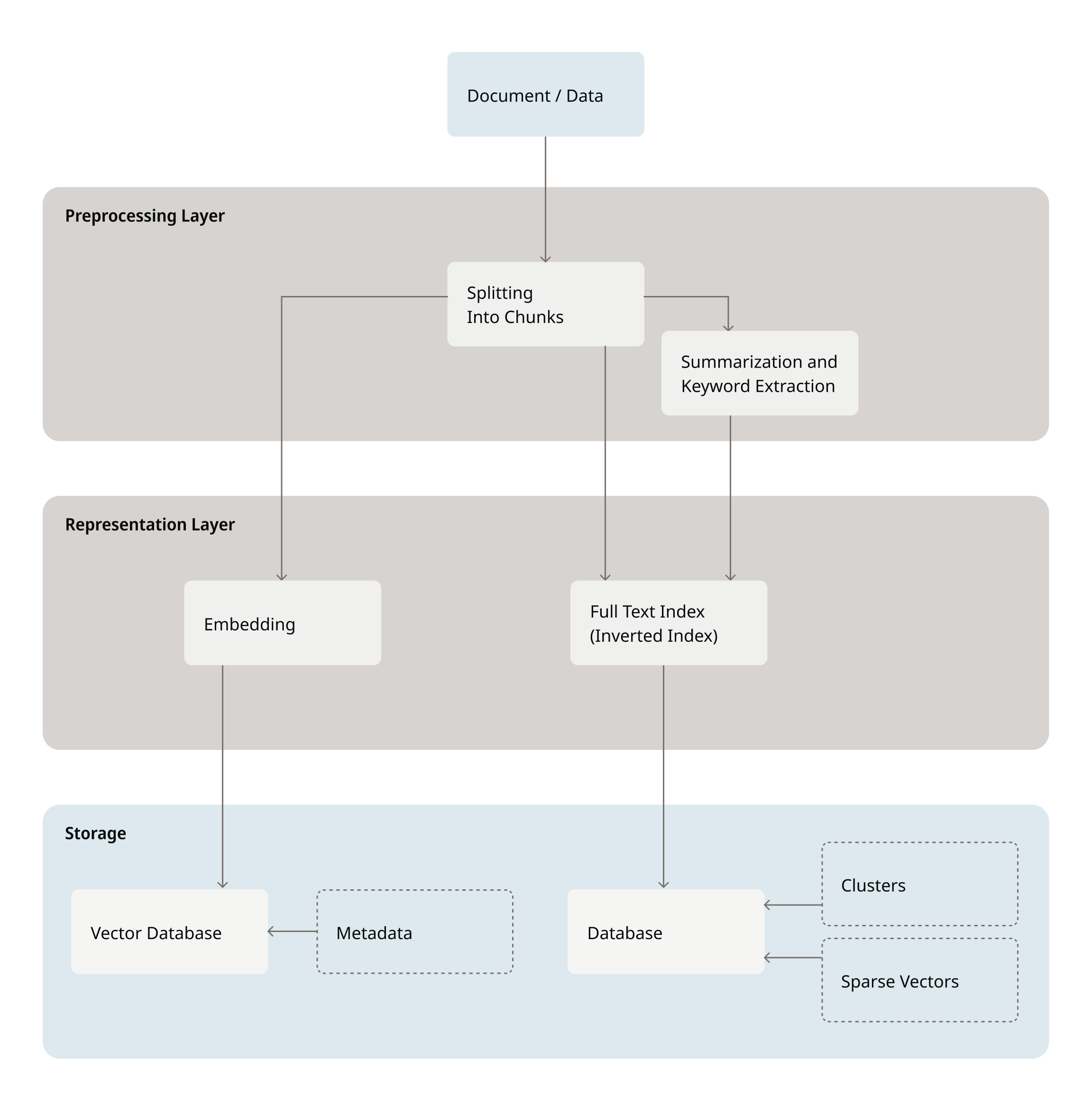
Knowledge Bases (KBs) organize data across data sources, including databases, files, documents, webpages, enabling efficient search capabilities. Here is what happens to data when it is inserted into the knowledge base.Documentation Index
Fetch the complete documentation index at: https://docs.mindsdb.com/llms.txt
Use this file to discover all available pages before exploring further.
INSERT INTO Syntax
Here is the syntax for inserting data into a knowledge base:
Default Batch Inserts
The batch inserts into knowledge bases (see “Insert Data using Partitions”) are enabled by default for all vector stores except PGVector. Note that in order for batch inserts to work by default, users must provide the
id_column when creating the knowledge base.To enable default batch inserts for PGVector, set the DISABLE_PGVECTOR_AUTOBATCH environment variable or the knowledge_bases.disable_pgvector_autobatch configuration variable to false (it is set to true by default).To disable default batch inserts, set the DISABLE_AUTOBATCH environment variable or the knowledge_bases.disable_autobatch configuration variable to true (it is set to false by default).To speed up data insertion, you can use these performance optimization flags:Skip duplicate checking (kb_no_upsert)This skips all duplicate checking and directly inserts data. Use only when the knowledge base is empty (initial data load).Skip existing items (kb_skip_existing)This checks for existing items and skips them entirely, including avoiding embedding calculation for existing content. More efficient than upsert when you only want to insert new items.
Handling duplicate data while inserting into the knowledge baseKnowledge bases uniquely identify data rows using an ID column, which prevents from inserting duplicate data, as follows.
-
Case 1: Inserting data into the knowledge base without the
id_columndefined. When users do not define theid_columnduring the creation of a knowledge base, MindsDB generates the ID for each row using a hash of the content columns, as explained here. Example: If two rows have exactly the same content in the content columns, their hash (and thus their generated ID) will be the same. Note that duplicate rows are skipped and not inserted. Since both rows in the below table have the same content, only one row will be inserted.name age Alice 25 Alice 25 -
Case 2: Inserting data into the knowledge base with the
id_columndefined. When users define theid_columnduring the creation of a knowledge base, then the knowledge base uses that column’s values as the row ID. Example: If theid_columnhas duplicate values, the knowledge base skips the duplicate row(s) during the insert. The second row in the below table has the sameidas the first row, so only one of these rows is inserted.id name age 1 Alice 25 1 Bob 30
id_column uniquely identifies each row to avoid unintentional data loss due to duplicate ID skipping.Performance optimization for duplicate handlingFor better performance when handling duplicates, you can use:kb_skip_existing = true: Checks for existing IDs and skips them completely (no embedding calculation, more efficient)kb_no_upsert = true: Skips duplicate checking entirely (fastest, use only for initial load into empty KB)
Update Existing Data
In order to update existing data in the knowledge base, insert data with the column ID that you want to update and the updated content. Here is an example of usage. A knowledge base stores the following data.Laptop Stand to Aluminum Laptop Stand.
Insert Data using Partitions
In order to optimize the performance of data insertion into the knowledge base, users can set up partitions and threads to insert batches of data in parallel. This also enables tracking the progress of data insertion process including cancelling and resuming it if required. Here is an example.-
batch_sizedefines the number of rows fetched per iteration to optimize data extraction from the source. It defaults to 1000. -
threadsdefines threads for running partitions. Note that if the ML task queue is enabled, threads are used automatically. The available values forthreadsare:- a number of threads to be used, for example,
threads = 10, - a boolean value that defines whether to enable threads, setting
threads = true, or disable threads, settingthreads = false.
- a number of threads to be used, for example,
-
track_columndefines the column used for sorting data before partitioning. -
errordefines the error processing options. The available values includeraise, used to raise errors as they come, orskip, used to subside errors. It defaults toraiseif not provided.
INSERT INTO statement with the above parameters, users can view the data insertion progress by querying the information_schema.queries table.
information_schema.queries table.
information_schema.queries table.
Chunking Data
Upon inserting data into the knowledge base, the data chunking is performed in order to optimize the storage and search of data. Each chunk is identified by its chunk ID of the following format:<id>:<chunk_number>of<total_chunks>:<start_char_number>to<end_char_number>.
Text
Users can opt for defining the chunking parameters when creating a knowledge base.chunk_size parameter defines the size of the chunk as the number of characters. And the chunk_overlap parameter defines the number of characters that should overlap between subsequent chunks.
JSON
Users can opt for defining the chunking parameters specifically for JSON data.type of chunking is set to json_chunking, users can configure it by setting the following parameter values in the json_chunking_config parameter:
-
flatten_nested
It is of thebooldata type with the default value ofTrue.
It defines whether to flatten nested JSON structures. -
include_metadata
It is of thebooldata type with the default value ofTrue.
It defines whether to include original metadata in chunks. -
chunk_by_object
It is of thebooldata type with the default value ofTrue.
It defines whether to chunk by top-level objects (True) or create a single document (False). -
exclude_fields
It is of theList[str]data type with the default value of an empty list.
It defines the list of fields to exclude from chunking. -
include_fields
It is of theList[str]data type with the default value of an empty list.
It defines the list of fields to include in chunking (if empty, all fields except excluded ones are included). -
metadata_fields
It is of theList[str]data type with the default value of an empty list.
It defines the list of fields to extract into metadata for filtering (can include nested fields using dot notation). If empty, all primitive fields will be extracted (top-level fields if available, otherwise all primitive fields in the flattened structure). -
extract_all_primitives
It is of thebooldata type with the default value ofFalse.
It defines whether to extract all primitive values (strings, numbers, booleans) into metadata. -
nested_delimiter
It is of thestrdata type with the default value of".".
It defines the delimiter for flattened nested field names. -
content_column
It is of thestrdata type with the default value of"content".
It defines the name of the content column for chunk ID generation.
Underlying Vector Store
Each knowledge base has its underlying vector store that stores data inserted into the knowledge base in the form of embeddings. Users can query the underlying vector store as follows.- KB with the default ChromaDB vector store:
Example
Here a sample knowledge base created in the previous Example section is inserted into.When inserting into a knowledge base where the
content_columns parameter was not specified, the column storing content must be aliased AS content as below.