How It Works
Here is the algorithm followed by Lightwood starting from the input data setup, through model building and training, up to getting predictions.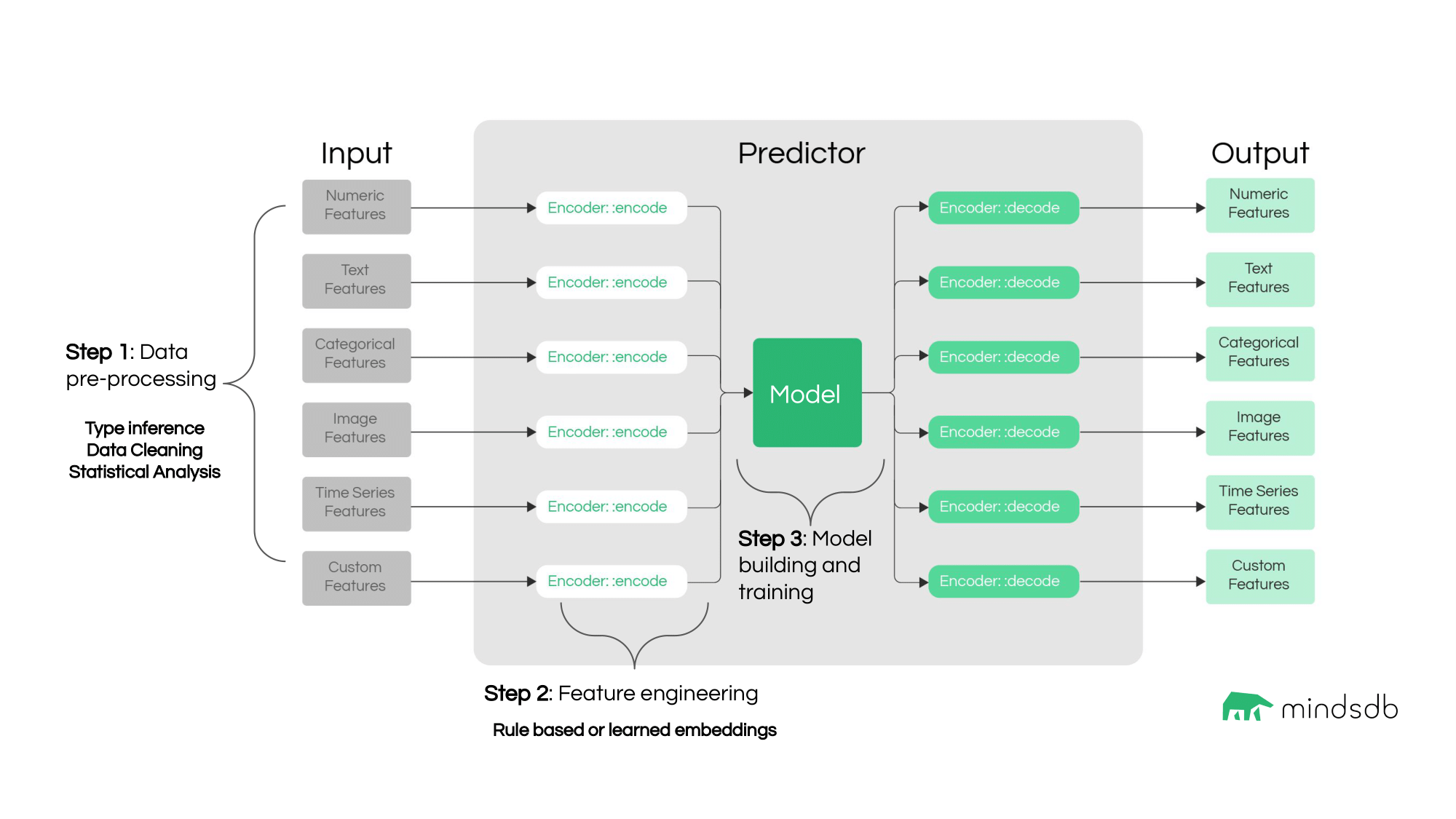
BaseMixer class.
To learn more about Lightwood philosophy, follow this link.
Accuracy Metrics
Lightwood provides ways to score the accuracy of the model using one of the accuracy functions. The accuracy functions includemean_absolute_error, mean_squared_error, precision_score, recall_score, and f1_score.
USING clause of the CREATE MODEL statement.
Here are the accuracy functions used by default:
- the
r2_scorevalue for regression predictions. - the
balanced_accuracy_scorevalue for classification predictions. - the
complementary_smape_array_accuracyvalue for time series predictions.
DESCRIBE statement.Tuning the Lightwood ML Engine
Description
In MindsDB, the underlying AutoML models are based on the Lightwood engine by default. This library generates models automatically based on the data and declarative problem definition. But the default configuration can be overridden using theUSING statement that provides an option to configure specific parameters of the training process.
In the upcoming version of MindsDB, it will be possible to choose from more ML frameworks. Please note that the Lightwood engine is used by default.
Syntax
Here is the syntax:encoders Key
It grants access to configure how each column is encoded. By default, the AutoML engine tries to get the best match for the data.
encoders and their options, visit the Lightwood documentation page on encoders.
model.args Key
It allows you to specify the type of machine learning algorithm to learn from the encoder data.
| Model | Description | |
|---|---|---|
| BaseMixer | It is a base class for all mixers. | |
| LightGBM | This mixer configures and uses LightGBM for regression or classification tasks depending on the problem definition. | |
| LightGBMArray | This mixer consists of several LightGBM mixers in regression mode aimed at time series forecasting tasks. | |
| NHitsMixer | This mixer is a wrapper around an MQN-HITS deep learning model. | |
| Neural | This mixer trains a fully connected dense network from concatenated encoded outputs of each feature in the dataset to predict the encoded output. | |
| NeuralTs | This mixer inherits from Neural mixer and should be used for time series forecasts. | |
| ProphetMixer | This mixer is a wrapper around the popular time series library Prophet. | |
| RandomForest | This mixer supports both regression and classification tasks. It inherits from sklearn.ensemble.RandomForestRegressor and sklearn.ensemble.RandomForestClassifier. | |
| Regression | This mixer inherits from scikit-learn’s Ridge class. | |
| SkTime | This mixer is a wrapper around the popular time series library sktime. | |
| Unit | This is a special mixer that passes along whatever prediction is made by the target encoder without modifications. It is used for single-column predictive scenarios that may involve complex and/or expensive encoders (e.g. free-form text classification with transformers). | |
| XGBoostMixer | This mixer is a good all-rounder, due to the generally great performance of tree-based ML algorithms for supervised learning tasks with tabular data. |
Please note that not all mixers are available in our cloud environment. In particular, LightGBM, LightGBMArray, NHITS, and Prophet.
model options, visit the Lightwood documentation page on mixers.
problem_definition.embedding_only Key
To train an embedding-only model, use the below parameter when creating the model.
problem_definition.embedding_only parameter), use the below parameter when querying this model for predictions.
Other Keys Supported by Lightwood in JsonAI
The most common use cases of configuring predictors useencoders and model keys explained above. To see all the available keys, check out the Lightwood documentation page on JsonAI.
Example
Here we use thehome_rentals dataset and specify particular encoders for some columns and a LightGBM model.
Explainability
With Lightwood, you can deploy the following types of models:- regressions models,
- classification models,
- time-series models,
- embedding models.
Regression
Regression
In the case of regression models, the Try it out following this tutorial.
target_explain column contains the following information:The upper and lower bounds are determined via conformal prediction, and correspond to the reported confidence score (which can be modified by the user).
Classification
Classification
In the case of classification models, the Try it out following this tutorial.
target_explain column contains the following information:The
confidence score is produced by the conformal prediction module and is well-calibrated. On the other hand, the probability_class comes directly from the model logits, which may be uncalibrated. Therefore, the probability_class score may be optimistic or pessimistic, i.e. coverage is not guaranteed to empirically match the reported score.Time-Series
Time-Series
In the case of time-series models, the Try it out following this tutorial.
target_explain column contains the following information:Embeddings
Embeddings
In the case of embeddings models, the Try it out following this tutorial.
target_explain column contains the following information:You can visit the comprehensive Lightwood docs here.